‘Met natural language processing creëer je nuance’
Artificiële intelligentie biedt een (ongestructureerde) bron van mogelijkheden voor het verbeteren van de zorg. Daar is Marieke van Buchem van overtuigd. Zij is PhD-kandidaat bij het Clinical Artificial Intelligence and Research Lab (CAIRElab) van het LUMC en sprak over dit onderwerp tijdens het online webinar ‘Herbruikbaarheid Zorgdata’, van het Healthcare Innovation Platform.
Samenvatting HIP-webinar
Download hier een pdf van het boekje ‘Herbruikbaarheid van zorgdata’ met een samenvatting van het HIP-webinar.

Marieke van Buchem studeerde geneeskunde en medische informatica en is nu PhD-kandidaat bij het onderzoeksproject ‘Responsible AI’ bij het CAIRElab. Ze houdt zich daar bezig met het gebruik van artificiële intelligentie (AI) binnen vrije tekst.
’’Mensen communiceren met het vertellen van verhalen. Over hoe het gaat, wat ze meemaken of doen. We leven alleen steeds meer in een datagedreven wereld. Daardoor is het vertellen van een verhaal niet altijd meer genoeg. Terwijl een verhaal juist kwalitatief is, houden we processen steeds meer kwantitatief bij. We meten en beoordelen. Er wordt ons steeds meer gevraagd om dingen cijfers te geven en om gestructureerde vragenlijsten in te vullen.’’
De zorg is hierin volgens de onderzoekster zeker geen uitzondering. ’’In een gesprek tussen een arts en een patiënt is het bijvoorbeeld vaak niet meer genoeg om alleen een verslag te schrijven. Er moeten ook gestructureerde datavelden worden ingevuld en checklists worden afgevinkt. Aan de kant van de patiënt komen er steeds meer vragenlijsten bij, zowel voor als na het consult. Die gaan over welke klachten iemand heeft, hoe de kwaliteit van leven wordt beoordeeld en hoe de zorg is ervaren.’’

Administratielast van zorgmedewerkers verlagen
Al die informatie is volgens de PhD-kandidaat ontzettend belangrijk om te verzamelen, maar de vraag is volgens haar wel of dat niet op een andere manier kan. ’’Het verzamelen kost veel tijd en zorgt voor administratielast voor zorgmedewerkers. Daarnaast gaat veel nuance verloren als een verhaal alleen wordt teruggebracht tot getalletjes.”
Om die reden is het op een andere manier verzamelen van data het onderwerp van haar promotieonderzoek. Marieke van Buchem creëert, implementeert en onderzoekt AI-modellen in de zorg met als doel om zorgmedewerkers te ondersteunen waar dat kan en te ontlasten waar dat nodig is. ’’Ik richt mij vooral op natural language processing.’’
Spraakherkenning in de spreekkamer
Om een goed voorbeeld te geven over wat je met natural language processing kunt bereiken, vertelt de onderzoekster tijdens het webinar over twee verschillende projecten waarmee ze bezig is. Haar eerste project gaat over spraakherkenning in de spreekkamer. ’’Dit is een project waarbij we proberen gesprekken tussen artsen en patiënten op te nemen, automatisch te transcriberen en samen te vatten.”
Het doel van het project is om de administratielast van de arts te verminderen, zodat de arts zich meer op de patiënt en zijn/haar verhaal kan richten. ’’In Amerika wordt dit al op diverse plekken gebruikt”, aldus Marieke van Buchem.

Er kleeft nog wel een nadeel aan de inzet van natural language processing. De techniek is erg taalspecifiek. Daardoor zijn de Amerikaanse systemen, die bijna alleen op Amerikaans-Engels werken, in Nederland niet bruikbaar. ’’Om die reden zijn we in het LUMC begonnen met de ontwikkeling van een eigen systeem. We zijn er nu ongeveer twee jaar mee bezig. Het opstarten heeft veel tijd gekost, maar ondertussen zijn we echt op snelheid.”
Tachtig procent symptomen uit gesprek te halen
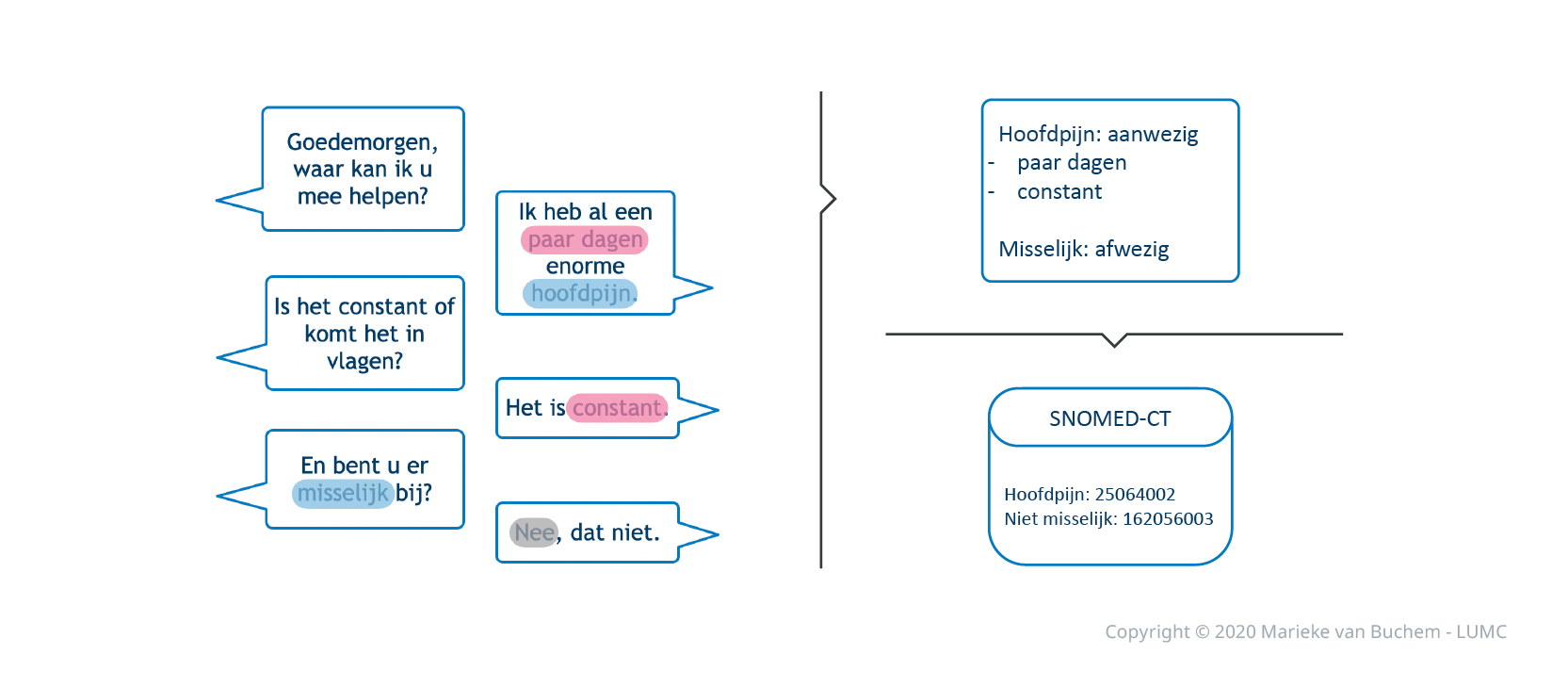
Het eerste model is sinds kort af en kan symptomen en eigenschappen van symptomen uit het transcript van het gesprek halen. Wanneer een patiënt aangeeft dat hij ‘misselijk’ is en ‘hoofdpijn’ heeft, dan worden die symptomen eruit gehaald. Als iemand zegt dat hij dat nu ‘drie dagen’ heeft, dan wordt de tijdsduur als eigenschap van het symptoom in het verslag opgenomen. Alles wordt gestructureerd weergegeven en er wordt direct een SNOMed-CT code aangekoppeld.
‘Wanneer een patiënt aangeeft dat hij ‘misselijk’ is en ‘hoofdpijn’ heeft, dan worden die symptomen eruit gehaald’
’’We kunnen nu ongeveer tachtig procent van de symptomen uit een gesprek halen’’, aldus Marieke van Buchem. ’’De eigenschappen worden er nog wat minder goed uitgehaald, maar dit model is ook nog maar getraind op zo’n vijftien opgenomen gesprekken. We hopen dat we met meer data nog betere resultaten kunnen behalen.’’
Het alleen benoemen van de symptomen in een samenvatting is nog niet voldoende, geeft de PhD-kandidaat aan. ’’Onze volgende stappen zijn om er ook diagnoses, medicatie en meer voorgeschiedenis van de patiënt uit te halen.’’
Helemaal niet meer typen als arts, dat duurt nog even
De arts en de patiënt lijken er al ontzettend blij mee, maar het gaat nog even duren voordat een arts helemaal niet meer hoeft te typen. ’’Het is een groot project met veel verschillende facetten. We verwachten dat de spraakherkenning vanaf half december ook in het EPD-systeem HIX werkt. Op die manier kunnen artsen makkelijker gesprekken opnemen en dat helpt ons bij het verzamelen van meer data.’’ Er zijn volgens Marieke van Buchem meer obstakels te overwinnen. ’’We moeten het transcript verbeteren. Een spreekkamer is niet de beste omgeving om een gesprek op te nemen. Daar is winst te behalen.’’ Ook moet volgens haar meer informatie uit het gesprek worden gehaald. Daarbij komt nog dat alle informatie die wordt verzameld in een overzichtelijke samenvatting moet worden gepresenteerd aan de arts. ’’Dat zijn aspecten waarbij verschillende expertises komen kijken. Daarom zijn we op zoek naar een marktpartij om ons model verder te ontwikkelen.’’
Blinde vlekken in vragenlijsten voorkomen
Het tweede project waar ze aan werkt is gericht op waardegedreven zorg. ’’Bij waardegedreven zorg gaat het niet alleen om de gezondheidsuitkomsten van een patiënt, maar ook hoe hij de zorg ervaart’’, legt de onderzoekster uit. ’’We zijn met dit project in het LUMC bezig om te kijken wat we hier kunnen doen voor het brughoektumor-zorgpad. Patiënten kregen hier altijd vragenlijsten mee om zo in kaart te brengen wat er nodig is om de zorg verder te verbeteren.’’
‘Bij waardegedreven zorg gaat het niet alleen om de gezondheidsuitkomsten van een patiënt, maar ook hoe hij de zorg ervaart.’
De vraag vanuit de Brughoektumor-afdeling is of er door al die gestructureerde vragenlijsten geen blinde vlekken zijn. ’’In zo’n gestructureerde vragenlijst staat vooraf al helemaal vast wat je gaat vragen’’, zegt de PhD-kandidaat. “Er is geen ruimte voor nuance. Als je vraagt hoe de patiënt de informatievoorziening vond, dan kan het antwoord ‘goed’, ‘niet zo goed’ of ‘slecht’ zijn. Maar waarom iets goed is of slecht, is daar niet uit halen.’’
Open vragen
Samen met het Brughoektumor-zorgpad is een eigen vragenlijst opgesteld die op vier domeinen open vragen stelt. ‘Hoe vond u de informatievoorziening’, is een voorbeeld van zo’n open vraag. ’’Maar we willen natuurlijk niet dat er een heel leger aan mensen nodig is om al die vragen te analyseren’’, zegt Marieke van Buchem. ’’Daarom hebben we geprobeerd daar een natural language processing-model bij te maken.’’
In dat model zijn vier domeinen opgenomen: informatievoorziening, benadering, samenwerking en organisatie. ’’De eerste stap is een sentimentanalyse. Van elke antwoord bepaalt het model of dat positief of negatief is. Daarmee krijg je al een mooi eerste beeld van hoe positief patiënten over de vier domeinen zijn. Daardoor zie je ook waaraan extra aandacht moet worden gegeven.’’

Het model kan ook preciezer laten zien wat mensen dan positief of negatief vinden. ’’En als je dan nog meer nuance wil, dan kan het model specifieke antwoorden terughalen. Op die manier krijg je een nog beter beeld van wat een patiënt precies bedoelt. En dan hoop je natuurlijk dat als je aanpassingen doet, dat je dat ook gaat terugzien in een volgende sentimentanalyse.’’
Dat maakt het kortom voor een model moeilijker om er gestructureerde data uit te halen, stelt Marieke van Buchem. Bij het Brughoektumor-project in het LUMC wordt nu bekeken of de vragenlijst die is opgesteld, kan worden opgenomen in het zorgpad.
Tips voor natural language processing
Marieke van Buchem geeft aan dat er nog veel meer mogelijk is met natural language processing in de zorg. ’’Natural language processing kan waardevol worden ingezet met als doel om de focus terug te brengen naar het verhaal van de patiënt.’’ Voor mensen die hier mee aan de slag willen, heeft Marieke nog een aantal tips:
- Zonder goede data krijg je geen goed model. Er is ook een goede voorbereiding nodig, want er gaat altijd een aantal preparatiestappen aan vooraf. Bij geschreven tekst heb je te maken met spelfouten of afkortingen die verschillend worden gebruikt. Ook zijn de transcripten niet altijd goed.
- Je moet goed nadenken over wat je als de gouden standaard kiest.
- Het betrekken van een marktpartij kan een project versnellen, maar is niet altijd nodig.
- Zorg dat je altijd de relevante partijen betrekt bij je project, onder wie clinici en data scientists. Om de data echt goed te kunnen begrijpen, heb je ook mensen nodig die bijvoorbeeld de data invoeren en beheren en natuurlijk de patiënten zelf.
- Kijk voor meer informatie op CAIRElab.
Meer lezen over datagedreven gezondheidszorg?
Meer info
-
Flexibele, kleine fabrieken om medicijnen sneller bij patiënten te krijgen
De medische wetenschap gaat met grote sprongen vooruit. Pfizer is bezig met de ontwikkeling van kleine, flexibele fabrieken die overal ter wereld kunnen worden neergezet.
-
Nationale Kanker en Werkdag: Doe het samen!
Dat werken met kanker niet vanzelfsprekend is, weet Edith Idoe-Stap uit eigen ervaring. Toen zij slokdarmkanker kreeg en weer aan het werk wilde, liep ze tegen een heleboel problemen aan. Nu, 15 jaar later, is Edith vanuit haar rol in de Groep Werk en Kanker een van de initiatiefnemers van de Nationale Kanker en Werkdag, een dag voor iedereen die in relatie tot werk geconfronteerd wordt met kanker.
-
Vermoeid? Ga shoppen maar niet sporten
Het is ongetwijfeld herkenbaar. Hoe klungelig je wordt als je vermoeid bent. Je gaat je koffie morsen, stoot je knieën aan je bureau en krijgt een deur in je gezicht als je die verkeerd opent. Wanneer je oververmoeid bent, werken je hersenen anders dan normaal. Dat heeft nadelen maar ook voordelen. Zo neem je als je moe bent veiligere besluiten.


